A Celery Scheduler for tracking and maintaining user workloads.
A Celery and Redis infrastructure to maintain and track user trainings, notebooks and deployments.
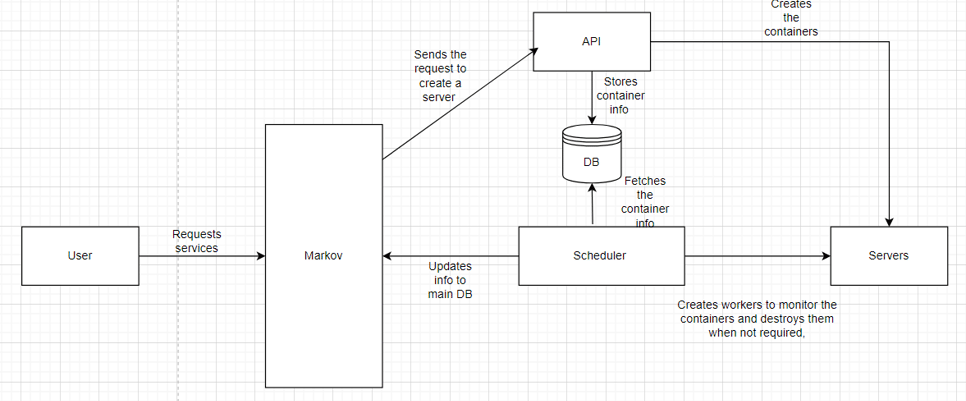
For a machine learning platform, tracking the status of the multiple user workloads such as ML training containers, Jupyter notebooks and ML deployments (Function as a Service) is one of the most critical tasks as many functionalities depends on the status of the workload.
For example, a user cannot look at the result of a workload if the workload is stuck in the "RUNNING" state but it actually got executed in the backend and the result is ready. Another example might be, a user cannot access a deployed ML model to use in their production environments if the deployment container is stuck in "DEPLOYING" state and never reaches the "READY" state.
Though the platform had a feature to achieve this, it revolved around the container sending the information about its status to the server and consequentially to the database. This had multiple points of failure and resulted in many issues such as a container being stuck "RUNNING" state and so on. A better, robust solution which was less prone to errors was needed.
I was part of the sub-team of 4 developers who took ownership of the new feature from conception to production. As a start, more states were introduced for the containers to reduce ambiguity. Multiple flows were designed for each type of container (The platform gives the user to create notebooks, run ML trainings, deploy their ML model to be used in production (Function as a Service)). A Django application was created which is connected to a Redis queue which send tasks to a Celery worker running in the application. The application was also connected to the database which keeps track of the statuses of these containers and also has added functionality to update the main database through an API call.
A typical cycle (lets take training containers for example) of a worker is as follows:
A worker receives a task to check the current status of all the RUNNING containers.
The worker would then run a query against the database to fetch all the RUNNING containers. But this is limited to 10 - 15 records so as to not overwhelm the worker which would result in the worker going down.
The worker would send requests to each container (The container has an API to return its current state) to get the current state.
It would then update the database for the corresponding records and also update the main database through an API call.
Time taken to complete (multiple workers deployed in production for different types of containers): 4 - 5 Sprints.
Tech Stack Used : Python, Celery, Redis, Django.