Buffered Docker Containers hosting the Jupyter suite of tools.
The rework which reduced the wait time to get a remote Jupyter lab by 90 Percent.
This blog post talks about my first feature implementation in Target. This was my first "major" project in full-time role as a software developer in Markov, the machine learning platform of Target. I was working in collaboration with a US team named "Dataminer" which provides a platform where any Target team member can request and use Jupyter labs, notebooks and many other tools to analyze their data (Given the importance of data analysis and volume of the data, the usage of the platform was huge with over 100-150 daily users). This resulted in an increased wait time to get a running "container" (Jupyter Lab/Notebook, etc.).
The way we tackled the problem is to analyze how the containers were created and maintained. Previously, the team used to send a request to the server hosting platform to run a specific Dockerfile with the user information tied to it. We introduced the concept of "Buffering" to this scenario. Essentially, we would maintain a collection of "Generic" (No user information is present as it sits in a buffer) containers and as the requests pour in, we would take in the user data and attach it to the container and return the details of the now newly customized container to the platform.
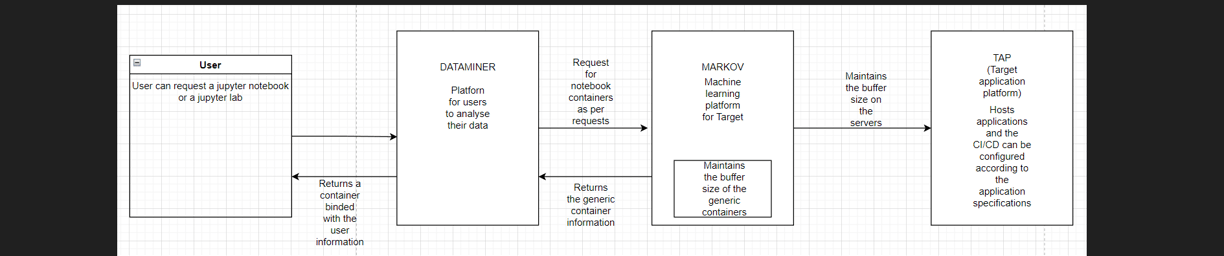
Above flow diagram is only a close estimation of the feature in production so as to not expose any sensitive data.
As mentioned above, we maintain a buffer to reduce the wait times. There are multiple buffers hosting different types of containers. The containers themselves would have internal APIs to configure itself with the provided user data. Our platform would then have multiple endpoints in different environments (dev, stage and prod) which Dataminer can use. They can do the following:
Increase or Decrease the buffer size based on usage metrics of their platform.
Refresh the buffer is necessary (For example, a new build has been released to introduce new features).
Request a specific container from the buffer. This would return the URL of the container.
Empty the buffer.
We would maintain the buffer by processing the number of requests our platform receives and spinning up containers as necessary. Ultimately, this feature would reduce the wait time of the platform by 90 percent from 5 minutes to approximately 30 seconds
Tech Stack and skills used: Java, Springboot, Docker, REST APIs, Swagger, Unit Testing and CI/CD.