Event Driven Emailing and Data Cleanup system for data science teams.
A feature where users can choose what happens to their old and unused ML models.
As the number of our platform users grew, we noticed that there was a significant number of ML models which were not being used (As only the best model is chosen for production by the data science teams). This would cause a lot memory to be wasted, memory which could have been used for a myriad of other processes and products.
This would need cleaning up old data which was not being used (If only it was that simple). But this would need consent from the creators of these Models. This feature implementation was taken up by myself from conception to production and this entire feature had to be deployed on all the three environments (dev, stage and prod). All the upcoming processes were carried out by maintaining clear communication with product managers, making sure we as a team are not getting off the track.
As a frontend, there would be a emailing system which would communicate to the data science teams that there were multiple ML models which were being unused and asking them to delete it from their end to save memory.
More Importantly, as a backend, there were several celery nodes running continuously to check (a task to check the database will be pushed to the Redis queue the worker will be monitoring) for old (accessed 30 days before) models and pulling the information related to that model, getting the team members associated with that model, constructing the customized message for that team including generating the links to delete that specific model and would update the database accordingly. But only if it was that simple, Again. There was a catch.
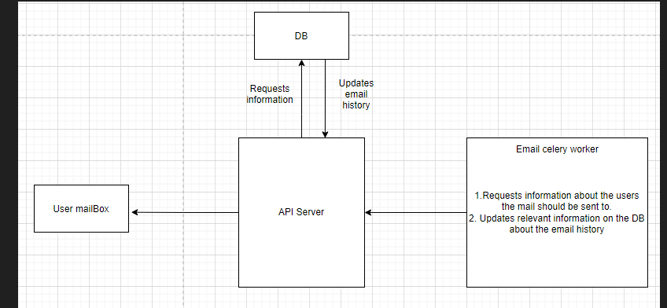
Above flow diagram is only a close estimation of the feature in production so as to not expose any sensitive data.
Some mails might get neglected (For example, a team member might leave the company or the mail might get buried) and the old models would stay there indefinitely. To ensure that those unused models were disposed for sure, the platform would wait for 50 days and would send out a final email mentioning that the model is scheduled to be deleted in 10 days. After 60 days, the model would be scheduled to be deleted for sure. Another celery worker monitoring a Redis queue would be checking for entries which satisfy this condition and would delete the models. The model could be stored in an Amazon S3 bucket or a HIVE DB. The worker should detect where the model is stored and should run the respective code according to the place where it was stored.
One of the primary factors taken into consideration when developing this feature was to maintain code modularity and reusability (which should be true for every feature implementation). As it turns out, there was similar issue with our clients training data. The same scenario would play out when the data scientist would be testing with their training data (featuresets) and would end up with multiple featuresets being generated with only the best one being put to use. This was an area of Improvement for the platform. Through the feature I developed, this was solved just by spinning up two new celery workers (for each environment), One to call the API to get the information about old featuresets and the other to dispose of older featuresets through the hive connector.
Time taken to complete: 3-4 Sprints.
Tech Stack and skills used: Python, Django, Python Celery, Redis, boto3, Hive connector, Docker, REST APIs,, Unit Testing and CI/CD.